На днях Яндекс запустил новый поисковый алгоритм под названием «Снежинск». Для меня это вдвойне интересная новость, так как я вырос в Снежинске. читать дальше →
21.11.2009
|
На днях Яндекс запустил новый поисковый алгоритм под названием «Снежинск». Для меня это вдвойне интересная новость, так как я вырос в Снежинске. читать дальше → 21.11.2009 Понимаю, что тема избита, но сам постоянно натыкаюсь на сайты, открывающиеся как с www, так и без.
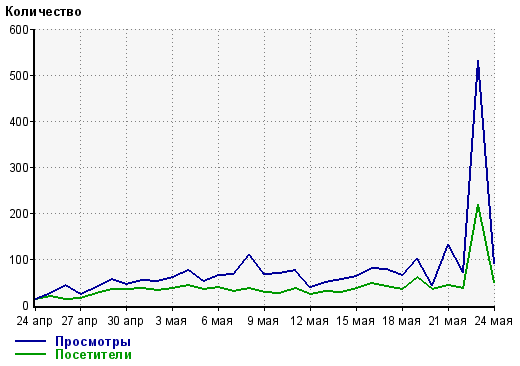
5.08.2009 Не секрет, что невозможно оптимизировать сайт под все виды поисковых запросов по данной тематике. Но даже если ваш сайт будет вылезать на 1 место по многим запросам, то часть клиентов все равно перейдет по 2,3… 10 ссылке в выдаче и возможно уйдет к конкурентам. А очень хочется, чтобы информация о фирме вылезала несколько раз подряд в топе. По всем этим причинам выгодно делать сайты-сателлиты. Сателлиты – это фактически сайты дублеры, но заполненые разным контентом. Пример 5.08.2009 Пару дней назад дал ссылку в комментарии в одном из постов на Хабре. Зайдя в статистику, обнаружил такую картину
30.05.2008 Файл Sitemap - это список страниц вашего веб-сайта в формате XML. Создание файла Sitemap позволяет обеспечить в Google наличие данных обо всех страницах на вашем сайте, включая URL-адреса, которые невозможно обнаружить в ходе стандартного процесса сканирования. Более подробно о Sitemap. Для Wordpress существует плагин Google Sitemap Generator for WordPress, который сгенерирует нужный Sitemap. Вот так выглядит sitemap для моего блога. 9.05.2008 Атрибут alt задает альтернативный текст, который выводится, если у пользователя отключено отображение графики. Это знает каждый веб-мастер. Кроме того, атрибут alt играет небольшую роль в ранжировании результатов поиска. Недавно обнаружил еще один плюс от использования атрибута alt читать дальше? 9.05.2008 <html>
<head>
<title>Yandex</title>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
</head>
<?php
if(!isset($_POST['submit'])) {
echo '<form method="post" action="">
<table>
<tr><td>Сайт: </td><td> <input name="site" type="text" size="30"> </td></tr>
<tr><td>Запрос: </td><td> <input name="zapros" type="text" size="30"></td></tr>
<tr><td>Количесвто страниц: </td><td>
<input name="count" type="text" size="30" maxlength="1" value="3"></td></tr>
</table>
<input type="submit" name="submit" value="Искать">
</form>';
}
else {
$pattern = '/<span style="color:#060;">'."\n".'(www.)*'.$_POST['site'].'(.*)/i';
$zapros = rawurlencode($_POST['zapros']);
$site = $_POST['site'];
$count = $_POST['count'];
// берем каждую страницу и парсим
for($p=0; $p<$count; $p++){
$link = 'http://www.yandex.ru/yandsearch?&p='.$p.'&text='.$zapros;
$content = file_get_contents($link);
// берем содержимое отдельной страницы и парсим
if(preg_match_all($pattern,$content,$page)) {
echo '<b>'.$_POST['site'].'</b><br>'.$_POST['zapros'].'<br>';
$content = explode('<div class="title">',$content);
// находим позицию сайта
for($i=1; $i<=10; $i++) {
if(preg_match($pattern,$content[$i])) {
$poz = $p*10 + $i;
echo '<a target="_blank" href="http://'.strip_tags($page[0][0]).'">'
.strip_tags($page[0][0]).'</a><br>';
echo 'Позиция: <a href="'.$link.'" mce_href="'.$link.'" target="_blank">'.$poz.'</a>';
exit();
}
}
}
}
echo 'нету :(';
}
?>
demo: http://ekimoff.ru/ya.php 9.03.2008 |
Интересные постыАбсент — сделай самРецепт медовухи Карабаш — черная точка планеты Дауншифтинг и фриланс Как свалить в Америку Как свалить в Таиланд Анкета на грин-кард Подводная лодка Б-396 Мирные ядерные взрывы в СССР Купил квартиру в Москве Про пенсии 
хочешь путешествовать?
учи английский!
|